Chapter 15 Testing
This chapter explains general principles of automated testing and gives technical instructions of integrating test cases into program development.
Remark: there are lecture videos with this content.
15.1 Automated Testing
Testing is an integral part of software development. It is one of the practices that distinguish a programmer being an engineer in contrast to a script kiddie. Initially, it may look for you as an additional effort without direct contribution to project progress, but, hopefully, with time, you will discover the usability of tests.
To understand the importance of automated testing let us take a global perspective. Nowadays, we are surrounded by software and depend on the correct functioning of programs. Software is used in administration, finances, medicine, telecommunication, transportation and many other domains. We assume that it is working correctly, but it may have critical software bugs with unpleasant or even dangerous consequences. You may lose your money, if somebody was not diligently testing an online shop software and your banking data got stolen. You may even lose your life, if the software of a plane was insufficiently controlled for quality and it crashed!
I guess you agree that testing is definitely crucial for safety- or mission- critical parts of software and even for any serious software. There is a general consensus about it and there are legal regulations for the extent of the quality assurance procedures for critical systems (e.g. SIL). Testing, together with other quality assurance procedures, increases our convenience that a piece of software is working correctly.
The importance of testing was recognised by big players in the IT domain. As an example, I would like to cite the summary of the Testing Overview chapter from the book on Software Engineering at Google: Lessons Learned from Programming Over Time.
The adoption of developer-driven automated testing has been one of the most transformational software engineering practices at Google. It has enabled us to build larger systems with larger teams faster than we ever thought possible. It has helped us keep up with the increasing pace of technological change. Over the past 15 years, we have successfully transformed our engineering culture to elevate testing into a cultural norm. Despite the company gowing by a factor of almost 100 times since the journey began, our commitment to quality and testing is stronger today than it has ever been.
We also want our small programs (for our own use) to work correctly. Testing helps us achieve a higher level of correctness in our programs. With test cases, we may actually define what we expect from our programs. Let’s learn it step by step.
15.1.1 Idea of Testing
Before we go into definitions related to testing and technical examples, I would like to give you a few analogies from daily life and a general concept of a test.
A test is an assessment intended to measure a test-taker’s knowledge, skill, aptitude, physical fitness, or classification in many other topics [Wikipedia].
Testing Activity
We deal with tests in our daily lives, education, medicine or science. In a broad view, by testing (putting under test) we can understand any process letting us know if an artifact or service is meeting our expectations, if an activity enables us to achieve a particular goal, or if a statement is true. Testing is required for validation and verification, the feedback we get from testing enables development.
Daily life analogies
In the first years of our lives, we are learning to speak in our native languages to express our needs and communicate with other people. In this process, even if unconscious, we constantly deal with testing: we need to pass the understandability test by an interlocutor. If the interlocutor, parent or sibling, can not understand us, we fail the test: we are unable to communicate our idea or request to this person. Even if failing a test may be discouraging, it is useful, as it leads to improvement of our skills — we learn on our mistakes. If the interlocutor gives us detailed and frequent feedback, we can learn effectively and quickly. Passing a test is always satisfying, but if the quality of the test is poor it may give a false conviction that all is fine.
From the example above, you can see that testing is done in an iterative way. Another example with a shorter iteration cycle is from our kitchens.
When we are cooking a meal, we season it to our taste. Usually it is an iterative process of adding salt, pepper, herbs or whatever other spices and next trying if it tastes as wished. If it is good, we are done (a taste test passed), if not we add more spices (a taste test failed). Cooking without tasting can be quite interesting to experience.
When we think about this example, we may discover that depending on the person the same meal maybe considered as tasty or not. Similarly, with testing we need to take into account who is assessing our system and also its purpose. Here is one more example showing how fitness to purpose is important.
This time let us look into our wardrobes. Let us imagine picking a cloth for a special occasion. At first, we think about the general dress code depending on the purpose/framework of the event. Btw. also our personal purpose may influence our choice, we may either go with the dress code or consciously break it. We would try different outfits and look in the mirror to test them. We are also restricted by the content of you wardrobe (shoes, accessories, …) to make a decision if they fit together. Going with another person, we may also consider his or her outfit when making a decision. If this person sometimes wears black, we should not assume that it will also happen next time, we should check the actual outfit.
Saying that, I would like to stress how important critical thinking is in testing. Ideally, when we are testing you should make no assumptions on anything. You should believe only facts, the results from your tests. However, you should also be critical of the tests themself… If you have this kind of skeptical and explorative mind, testing can be a satisfying and fun activity.
Based on the intuition we have from the aforementioned examples, let us look at the definition of software testing.
Software Testing
Definition 15.1 Software testing is an investigation conducted to provide stakeholders with information about the quality of the software product or service under test.
It means, we need to define what qualities we need to consider and who is interested in them. We will discuss some aspects in the next section, now let’s focus on aspects essential in our course.
We will define the criteria, which are mostly focusing on functional correctness of our programs, it means checking if they deliver expected results. We may compare our expectations against programs or compare results from different programs or different versions of a program. We will mostly define and conduct tests in an iterative way. After conducting tests, for every single test (case), we will see if our program
- passed it, it means the expected result is equal to the actual result or behavior, or
- failed it, it means the expected result differs from the actual result or behavior.
We will need to analyze test reports to see which tests our programs failed and which passed to make the decision on further programming steps.
Example Test Case
For better understanding of passing and failing test cases, we will look at very simple examples.
Please mind that there is no point of testing arithmetics or other functionality provided by a programming language interpreter. We start with an oversimplified, not realistic example to be able to focus on the testing mechanism without a need of understanding complex code. We will deal with a realistic example in the Test driven development by example section.
Let’s start with something obviously correct: we expect that 1 + 2 is equal to 3. If we want to define a test case for it we need to specify what we are testing/executing (1 + 2), and what we are expecting (3). If we run a taste case, the result from the statement under test (3) will be compared with the expected result (3). For this test case, they will be the same, so the test case state will be OK/passed.
Now, let’s check something obviously wrong: we expect that 1 + 2 is equal to 2. For this test case, the result from the statement under test will differ from the expected result, therefore the test case state will be failed.
Summarizing and comparing the two test cases we have:
| test case: | 1 + 2 ?= 3 | 1 + 2 ?= 2 |
|---|---|---|
| to be executed | 1 + 2 | 1 + 2 |
| expected result | 3 | 2 |
| obtained result | 3 | 3 |
| test case state | passed/OK | failed |
These test cases are not really meaningful, we do not need to test built-in functionality, but they were included to illustrate the new concepts. And usually, our expectations (from test cases) are correct, however, it is possible to make mistakes in test specification, too.
If you want to look ahead and see how it technically may look like in R open the next box.
We will learn later how to define test cases in R using tinytest, but let’s shortly look at the aforementioned example test cases.
To define a test case using tinytest, we will call the function expect_equal(), where as arguments we can use any R statement.
Here, as a value of the first argument we will put statement under test,
and for the second, the expected result.
## ----- PASSED : <-->
## call| expect_equal(1 + 2, 3)Simulary, for the second test case:
## ----- FAILED[data]: <-->
## call| expect_equal(1 + 2, 2)
## diff| Expected '2', got '3'15.1.2 Aspects of Testing
Testing methods are related to software engineering, so we need to learn in the following some aspects to see a big picture on testing:
- level of automation,
- scope of testing,
- testing workflow,
- extent of testing.
Level of Automation
At first, we have to consider the level of automation. We can also consider it as a level of interaction needed to test a program.
On one hand, we have manual testing, where a person acts as an end user, who needs to start a program and inspect if it is behaving as you expected. This is a very inefficient approach, because one needs to repeat this activity every time the program was modified. It is also error-prone, as one can skip some test cases or overlook bugs.
On the other hand, we have non-interactive testing, which means that the interaction between a human and the computer is not required to conduct the tests. Automated tests are much more efficient. In this case we just run one program to test another one.
As a result of the automated testing, we will obtain a report with information on passed and failed test cases.
To be able to conduct (automated) testing in a systematic way, we need to define test cases.
Definition 15.2 A test case is a specification of the inputs, execution conditions, testing procedure, and expected results that define a single test to be executed to achieve a particular software testing objective, such as to exercise a particular program path or to verify compliance with a specific requirement. Test cases underlie testing that is methodical rather than haphazard.
It means, each test case should test some specific behavior of the program. In the test case, we need to specify
- what piece of program we execute, e.g. a function,
- using which data, e.g. values of arguments,
- what is the expected result, e.g. return value.
In this course, luckily it is pretty easy to test the programs, because they are relatively small, simple and focusing mostly on computations or data manipulations. If we would have user interaction it would become harder, as we would need to simulate it. Testing graphical user interfaces is technically more challenging. Moreover, there are aspects which can be tested only by humans, like for example usability or graphical design. Similarly, acceptance testing by client of a product is something partially objective (e.g. functionality) but partially subjective (e.g. user-friendliness).
Scope of Testing
Software testing involves the execution of a software component to indicate the extent to which a component or system under test:
- meets the requirements that guided its design and development,
- responds correctly to all kinds of inputs,
- performs its functions within an acceptable time,
- it is sufficiently usable,
- can be installed and run in its intended environments, and
- achieves the general result its stakeholders desire.
Each of criteria determine the scope of testing. Taking it as a guideline, we can define different types of tests. Starting from the most technical level, we have:
- Unit testing is testing of single pieces of programs (code). In our course, we will test functions. See the definition below to get a broader sense of unit testing.
- Integration testing is required for more complex programs. Here, tests are conducted in respect to design, where interacting components are defined. In this type of testing, we want to investigate if components (at least two) are working together in the expected manner.
- System testing is required if we want to know if the system as a whole is working as specified in the requirements.
- Acceptance testing is the final step in the decision if we succeeded in development of a software system. Here, we test our system against client needs, so actually in this step clients must be involved. Depending on the development workflow (see below), they may be involved only at the end of the project or multiple times within development cycles.
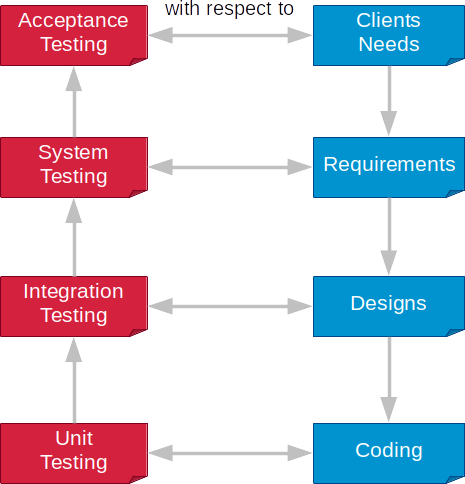
In this course, we will focus almost entirely on unit testing. Sometimes, we will compare behavior of two functions or define a simple integration test.
Definition 15.3 Unit testing is a software testing method by which individual units of source code — sets of one or more computer program modules together with associated control data, usage procedures, and operating procedures—are tested to determine whether they are fit for use. To isolate issues that may arise, each test case should be tested independently.
Testing Workflow
Yet another aspect is testing workflow. There are different options when we can define and execute test cases.
In classical waterfall model based approach, project activities are broken down into linear sequential phases. One of the phases is coding and when it is completed tests are specified and executed.
Late definition of tests does not give the full advantage of defining tests and may feel as an additional burden. This may lead to skipping testing completely or just doing them in a messy and whatever way.
After some time more dynamic and iterative approaches emerged, which focused on longer or shorter development cycles. One of them, considering testing as the first class member of software development, is test-driven development.
Definition 15.4 Test-driven development (TDD) is a software development process that relies on the repetition of a very short development cycle: requirements are turned into very specific test cases, then the code is improved so that the tests pass. This is opposed to software development that allows code to be added that is not proven to meet requirements.
I advocate to use the test-driven development approach and iterative approaches, in general.
In TDD, we start with writing a few initial test cases followed by writing a program that passes all of them. Defining test artifacts first forces us to start with thinking about what we want to be implemented in particular steps. The test cases are our precise requirements specification saying what we expect from our program and the results are giving a clear answer if the program fulfills them or not. Without tests, we would have a harder time in saying if the program fulfills the requirement given as text. We could not automate this check and even could misinterpret them. Moreover, by defining tests first you do not risk that you will forget or neglect writing them.
Once the program passes all test cases, we can start a next iteration, when we extend our test suite by defining more test cases and writing programs against tests.
Small iterations are important, because when we define a high number of tests (or all) first and start to program against them, it can be demotivating and overwhelming to have many failing test cases. Moreover defining many/all tests up front may be hard, as we may not have initially all the knowledge about the system, we may not know all facts influencing behavior of the program.
TDD is well applicable for programs written by one person, as it is easier to switch between testing and programming. When more people are involved in writing software, such dynamic approaches need to be synchronized. As in our course, you program alone, I would again recommend to use this approach and see testing as a helpful mean in defining what we want to achieve.
Extent of Testing
The last aspect is the extent of testing. There are obviously two extremes:
- testing everything, which is hardly achievable, but sometimes done for safety- or mission- critical parts of software (e.g. aircraft flight control systems),
- testing nothing, unfortunately this is quite common, also in industrial software.
In general, extremes are not good, and also not in the case of testing. In this course, the extent of testing is predefined. However, beyond the course you have to make the decision for yourself what is meaningful for your task. In general, test everything you don’t want to break.
I hope that after this course you will recognise the value of testing and keep using it. The minimalist approaches that I would recommend are following regression testing and testing for refactoring.
Definition 15.5 Regression testing is re-running tests to ensure that previously developed and tested software still works after a change. If not, that would be called a regression. Changes that may require regression testing include bug fixes, software enhancements, configuration changes, and even substitution of electronic components. As regression test suites tend to grow with each found defect, test automation is frequently involved.
In regression testing, the test suite is growing together with the program. As you can see from the definition every time you detect a bug while running your program you should write a test case to prevent reintroducing this bug later. Additionally, before doing software enhancements, such as refactoring, you should extend your test suite.
Definition 15.6 Code refactoring is the process of restructuring existing computer code without changing its external behavior. Refactoring is intended to improve the design, structure, and/or implementation of the software (its non-functional attributes), while preserving its functionality.
Personally, I would not do any serious refactoring of my program without testing. It just feels more secure to play around with the program while being able to run the test cases.
If you still are not convinced on automated testing, I would support my personal views gain with lesson learned from programming at Google. In their book almost 20% of content is directly dedicated to testing.
Among others, the following benefits are mentioned in the book (selection):
- less debugging - probably by now you experienced how hard it may be to find bugs (logical, semantical mistakes), therefore you could see testing as a prevention mechanism,
- increased confidence in changes - code is changing over time either in process of debugging, refactoring or just growing, tests give you confidence that your changes will not break the existing code and you may enjoy the process of modification,
- improved documentation - as code is read more often than written, tests are important means helping to read and understand the code, tests are executable documentation, it does not matter if they are used explicitly as documentation (like doctest in Python) or as testing code (like tinytest in R), they are verified source of information about your code,
- thoughtful design - if you have testing in mind, you need to write your programs in more modular way, design small functions with meaningful parameters and without side-effects, which leads you to a better design.
Even if you spend a lot of time on writing tests, in the long-term, it will speed up the development of your project.
15.1.3 Test Suite
Creating a test suite, a collection of test cases, is the most critical activity in systematic testing of a program. When defining a test suite, we have to think about what our goal is, what behavior we want to test and to what extent.
An important aspect which determines how we approach defining a test suite is the fact that we have access to the source code of a program under test. If we can and want to look into the source code, we talk about white box or glass box testing, on the opposite, if we define a test suite without looking into the source code, we talk about black box testing. There is also a mixture of white and black box testing, which is called gray box testing, but we will focus on the cases with clear distinction.
In white box testing, we have access to the source code of a program under test. It means, we know the structure of the program, see the statements, including control flow statements and used conditions. We have this situation in our course and also in projects where there is no strict separation between programmers and testers. It can be related to a small size of a project or used methodology, e.g. TDD.
In black box testing, we have no access to source code, so we need to test it from an external, end-user perspective. Black box testing is possible also without having programming skills as it focuses on the behavior of the program. It can be done if we do not have access to the source code (e.g. commercial, close code software) or we want on purpose separate the programming and testing activities/teams (e.g. mission critical systems).
Depending on the type of testing, we have different techniques for defining a test suite.
White Box Testing and Coverage
As in white box testing, we can see the source code and therefore can apply techniques to systematically cover the entire program with test cases.
Definition 15.7 Test coverage is a measure used to describe the degree to which the source code of a program is executed when a particular test suite runs.
A program with high test coverage, measured as a percentage, has had more of its source code executed during testing, which suggests it has a lower chance of containing undetected software bugs compared to a program with low test coverage.
There are many coverage criteria, let’s focus on a few basic ones:
- Function coverage aims to have each function in the program called at least once,
- Statement coverage aims to have each statement in the program executed at least once,
- Branch coverage aims to have each branch of each control structure (such as in if statements) executed.
As in our course, we are at the level of defining functions, the first criteria is too weak for us, so let us focus on the second and third one and understanding the difference between them. Let’s do it in very simple examples.
Example 1
As an example, we will take a function definition with two parameters, one if-statement and two return statements. In this very simple example, we will analyze two criteria: statement and branch coverage.
ab_fun <- function(a, b) {
if (a && b)
return(2) # the first statement to test
return(1) # the second statement to test
} We will start with statement coverage. We have to check how many non-control flow statements we have.
We have two such statements, returning values from our simple ab_fun() and these statements we should test.
To have complete statement coverage, we need to define two test cases calling this function with different
parameters to reach each of statements, e.g.
For this simple example, if we consider branch coverage, we will obtain exactly the same test cases. In our function, we have only one if-statement, so we have an if-branch (returning 2) and an else-branch (returning 1).
Example 2
Let’s slightly refactor the definition of the function to see if this is always the case that whatever criteria we will use, we obtain the same number of test cases. We will change the structure of the body of the function by adding one more branch to our function, but no new statement. The behavior of the function will remain the same (we can test it!).
ab_fun <- function(a, b) {
if (a)
if (b)
return(2) # the first statement to test
return(1) # the second statement to test
} As we can see in the code, we have the same statements, so the statement coverage will remain the same.
The control flow, however, is different. Now, we can get 1 as the result of the function
either going through outer if-branch and inner else-branch or just by entering outer else-branch.
Therefore, we need one additional test case for branch coverage.
expect_equal(ab_fun(TRUE, TRUE), 2)
expect_equal(ab_fun(TRUE, FALSE), 1)
expect_equal(ab_fun(FALSE, FALSE), 1) # the new test case For this example, we have more test cases to get the complete branch coverage than for complete statement coverage.
In general, if the tests have complete branch coverage then we can say it also has complete statement coverage, but not the vice versa.
Let’s now go out of the white box…
Black Box and Boundaries
…and dive into the black box. Now we can not look into the source code. Therefore, we have to observe the behavior of the program under test from outside. One possible method to analyze the behavior in a systematic way is to use the equivalence partitioning and boundary value analysis.
The input of the program should be divided into equivalence classes. For input values from the same class, we would obtain the same result.
For example, let us consider a function which says if a grade is positive or negative. We would have two equivalence classes: 1 - 4 as positive grades and additionally, 5 as the negative grade (in the Austrian education system). We could add one more class, invalid grade for all numbers below 1 and above 5. Optionally, we could have “invalid too low” and “invalid too high”.

For testing, we could take whatever value from a class and obtain the same result. It means that having multiple test cases for the same class usually does not increase the probability of program correctness.
In our example, we could pick up -1, 3, 5, 8 for testing.
When we consider usage in test cases, not all values from a class are equally effective when testing. The values closer to boundaries between classes are ideal candidates for testing.
For example, from the positive grade class we could pick 1 and 4, as closest to the “invalid too low” and “negative” classes. Going this direction we would need to pick the following values: 0, 1, 4, 5, 6 for testing.
It is helpful to visualize values, equivalence classes and boundaries to pick up the values for testing.

If we imagine changing behavior of the program in the way that the boundaries would slightly move, our values should detect these changes. I believe it is intuitive, but a bit abstract. Therefore, we will look a bit deeper to understand this mechanism.
In our example, for a positive grade we may have the following condition:
1 <= value <= 4. For our testing values: 1 and 4, we will getTrue. Now, if we make a mistake in the condition and use1 < value <= 4, the test case with 1 will detect it, because we will obtainFalse, where we expectedTrue. Of course, any other number from this class (2, 3, 4) would not detect this change. On the other hand, 4 is protecting the other side of the condition (see the table below).
| testing value | 1 <= value <= 4 | 1 < value <= 4 | 1 <= value < 4 |
|---|---|---|---|
| 1 | True | False | True |
| 2 | True | True | True |
| 3 | True | True | True |
| 4 | True | True | False |
| 5 | False | False | False |
It is relatively easy to use the equivalence partition and boundaries values analysis, when we deal with one whole number input value. For a continuous scale, we would need to decide on the accuracy with which we would pick the closest value. Accuracy should be something meaningful for our domain.
For example, if we would have age in years as a real number, we could set the accuracy to one day, which would mean 1/366 (0.0027) years.
2D Example
Let’s look now at an example with two input values. We will consider an assessment rule, where you should take two exams and could score between 0 and 100 in each of them. An exam is passed when more than 50 points are scored.
For a single exam, we have the following equivalence partition:

Additionally, to pass a course, we may need to pass both exams. Taking into account both exams will extend our input space to two dimensions.
Remark on the graphical representation: Points not filled are excluded from a particular area.
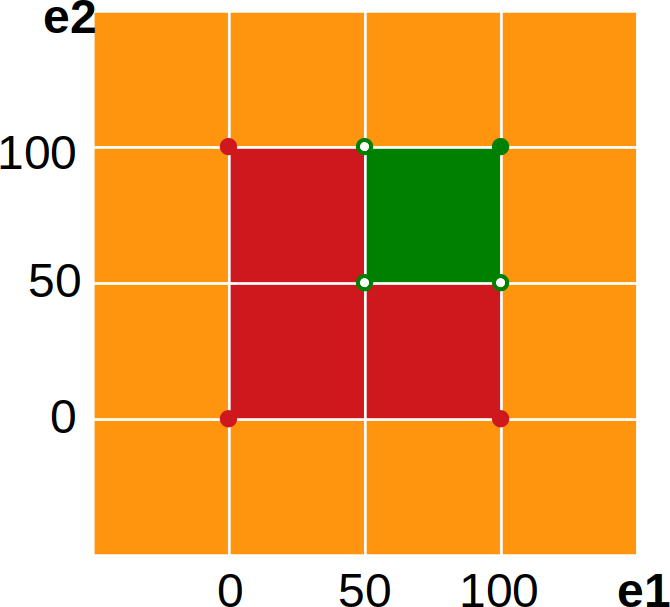
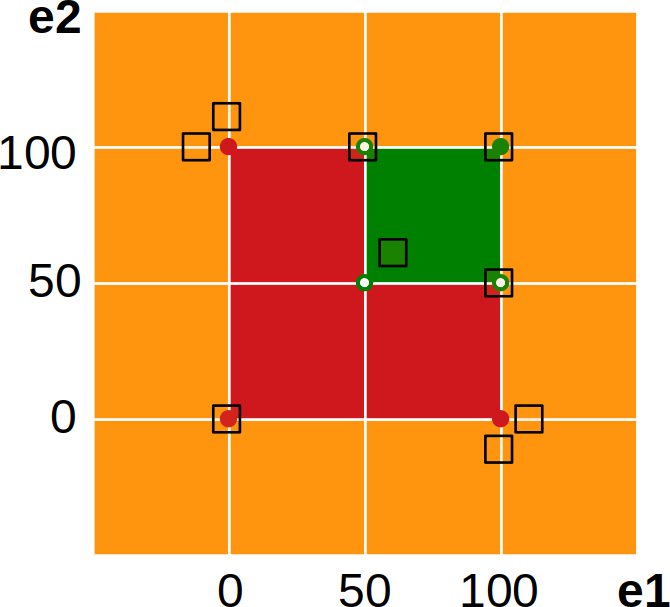
Now, we will need to take care to pick up test values to cover all corners. To reduce the overall number of tests, we can do it also indirectly, i.e. values from two test cases may create a virtual one, e.g. with (50, 100) and (100, 50) also (50, 50) is covered.
15.1.4 Defensive Programming
Defensive programming is an approach intended to ensure the continuing function of a program under unforeseen circumstances. One of the goals is to make a program behave in a predictable manner despite unexpected inputs or user actions. To achieve that we need to include additional conditional execution (sanity checks) and/or deal with possible errors/exceptions (error handling).
Trade-offs
Implementing mechanisms required for defensive programming requires additional resources (time). Therefore, the first question we would need to ask is when it does pay to do this. It depends on the usage scenario of our program, in particular sources of data and communication with users.
Sources of data
Unpredictable sources of data should be checked for correctness. Such unpredictable sources of data may be user input or calls from third-party programs. We have absolutely no guarantee what data a user will feed to our program, neither do we have control over arguments somebody else is using for calling our functions. In such situations it is better to check if the data is appropriate for our purpose. If invalid data may cause problems, we should definitely check its correctness.
Secure sources of data do not need to be checked. If we are the only user of our program, or another team member or trusted person, and we have only internal communication within our program, we may assume that data passed around is correct.
Communication with a user
If you need messages for more informative error messages you should use exception handling. If we rely on built-in error handling and standard programming language error messages they may be unclear to a user who does not know this particular programming language. If we define our own error handling, we can make them domain-specific.
If you need to end your program gracefully and safely. If you don’t want users see just tons of traceback lines he or she can not understand and risk a damage or lost of data, you need to foresee situations when your program may crash.
If none of the above is relevant to you, you could rely on standard exception handling.
For example, our program would run for a week to collect and process some data. After it is finished, it would ask a user how many records of data should be saved. And the user will give a text instead of a number.
When our program uses this user input for slicing a vector, we will get an error message, for example,
Error in 1:"text" : NA/NaN argument
In addition: Warning message:
NAs introduced by coercion If we do not deal with this issue, the program will stop and no data will be saved. Loss of (computation) time! In this situation, we should definitely check user input.
Moreover, we should write more informative error message, for example
You gave an incorrect number. The number should be a positive whole number smaller than 666. Please try again.
(666 is the number of all records).
In general, we need to answer to ourselves if a case may be problematic and if the answer is yes we should program precauciones, otherwise, we do not need to care about it.
Location of sanity checks
If you want to add sanity checks to your program you can use precondition, postconditions or invariants.
Precondition is a condition that must always be true just prior to the execution of some section of code. In the function’s precondition you can check all constraints on the function’s arguments (types, values).
For example, before you start a conversion of temperature from Celsius to Kelvin, you may check if given temperature is a number and it is not lower than the absolute zero.
Postcondition is a condition that must always be true just after the execution of some section of code. In the function’s postcondition you can check all constraints on the function’s result (e.g. range).
In the same example, we could check if the temperature in Kelvin is not lower than zero.
It is not so much relevant to this course, but for completeness I will also introduce the definition of an invariant. Invariant is a condition that must always be true during the execution of a program, or during some portion of it (e.g. inside a loop).
In aforementioned examples, I always mentioned having conditions inside functions. This is one approach, the other would be to have checks outside functions. What is better depends on a usage scenario, in general, we should aim to have only one check.
If we have user input only in one place and we know the restrictions on this input, we could check type and content correctness there. If we have several ways how we can pass data to our function, it is better to check the data (once) inside the function. Checking data inside a function has usually two advantages: the check typically happens only once and it is close to specification and usage.
15.1.5 Glossary
Collection of the definitions from the chapter text.
Software testing is an investigation conducted to provide stakeholders with information about the quality of the software product or service under test. More in Wikipedia
A test case is a specification of the inputs, execution conditions, testing procedure, and expected results that define a single test to be executed to achieve a particular software testing objective, such as to exercise a particular program path or to verify compliance with a specific requirement. Test cases underlie testing that is methodical rather than haphazard. More in Wikipedia
Unit testing is a software testing method by which individual units of source code — sets of one or more computer program modules together with associated control data, usage procedures, and operating procedures—are tested to determine whether they are fit for use. To isolate issues that may arise, each test case should be tested independently. More in Wikipedia
Test-driven development (TDD) is a software development process that relies on the repetition of a very short development cycle: requirements are turned into very specific test cases, then the code is improved so that the tests pass. This is opposed to software development that allows code to be added that is not proven to meet requirements. More in Wikipedia
Regression testing is re-running tests to ensure that previously developed and tested software still works after a change. If not, that would be called a regression. Changes that may require regression testing include bug fixes, software enhancements, configuration changes, and even substitution of electronic components. As regression test suites tend to grow with each found defect, test automation is frequently involved. More in Wikipedia
Code refactoring is the process of restructuring existing computer code without changing its external behavior. Refactoring is intended to improve the design, structure, and/or implementation of the software (its non-functional attributes), while preserving its functionality. More in Wikipedia
Test coverage is a measure used to describe the degree to which the source code of a program is executed when a particular test suite runs.
A program with high test coverage, measured as a percentage, has had more of its source code executed during testing, which suggests it has a lower chance of containing undetected software bugs compared to a program with low test coverage. More in Wikipedia
15.2 tinytest in R
In R, there are multiple packages to define unit tests or to conduct advanced testing procedures. One of the easiest to use is packages is tinytest: Lightweight and Feature Complete Unit Testing Framework.
15.2.1 Loading package
To use this minimalistic approach with the tinytest package, you may need to install once
(install.packages("tinytest")).
Next, you need to load the package:
We can define tests in our R script file, but it is better to define them in a dedicated file, which we may run
calling function run_test_file().
15.2.2 Test case
Let us take a closer look at definition, interpretation and result of a test case in a very simple example.
Test case definition
A test case in tinytest is just a function call. There are different functions, which will be introduced here by
example.
Let us start with the same example as in the previous chapter.
In this simple test case, we have a call of the
expect_equal(), which takes two statements and compares them. Additionally, we can put a comment to be displayed if the test case fails.
Test case interpretation
In our example, we expect that
1 + 2is equal to3.
We always compare two objects. The objects may be given directly as parameters or as statements to be executed. Their order does not really matter for the function result. However, it is better to keep it consistent. The messages assume that the first argument as an object under test (current object) and the second one as expected result (target object).
Next the comparison of obtained and expected result is done.
In our example,
3(as the obtained result from1 + 2) will be compared with3(as the expected result). As they are equal, the test case will be OK (pass).
If we have a test case in our file, it will be executed,
if it is in another file, we can execute all test cases using run_test_file() function.
Test case result / report
The tinytest will show a report for a single test case or multiple test cases.
In our example, the test case was OK (passed), as it can be seen in the below report.
## ----- PASSED : <-->
## call| expect_equal(1 + 2, 3, info = "testing addition operator")
## info| testing addition operatorIf we supposed to use addition in our statement under test, but we made a typo and used
-instead of+, our test case will fail. Additionally, we will obtain information that the problem was with data, what was the difference and the info that we used in the function call.
## ----- FAILED[data]: <-->
## call| expect_equal(1 - 2, 3, info = "testing addition operator, wrong expectation")
## diff| Expected '3', got '-1'
## info| testing addition operator, wrong expectationIt is also possible that we put an incorrect value as expected result and in this case our test case will fail. Therefore, it is important to double-check expected results.
## ----- FAILED[data]: <-->
## call| expect_equal(1 + 2, 4, info = "testing addition operator, wrong expectation")
## diff| Expected '4', got '3'
## info| testing addition operator, wrong expectationFor multiple test cases a summary can be shown as well, containing a number of failed test cases and the total number of test cases. Interactive reports are also shown by integrated development environments, e.g. Rstudio, where you can click on the test case and jump to the its definition.
15.2.3 Example test cases
In this section, we will use very basic R statements to focus on the testing mechanism. Again, you do not need to test built-in functionality, which was used here to have possibly simplest examples. In the next section, we will have examples of testing a user-defined function.
Usage of variables
When testing, we can use any variables that are visible, when the expect_equal() function is called.
## ----- PASSED : <-->
## call| expect_equal(a + b, 3, info = "testing addition operator on variables")
## info| testing addition operator on variablesLevels of comparisons
So far we used expect_equal(), but in R objects can be compared at different levels of strictness.
Therefore, we can use expect_equivalent(), which is less restrictive and ignores attributes,
or we can use expect_identical(), which is the most strict test and compares all aspect of object including where they
are stored.
## ----- PASSED : <-->
## call| expect_equivalent(a, b)## ----- FAILED[attr]: <-->
## call| expect_equal(a, b)
## diff| Attributes differAs we can see, expect_equivalent() ignored the attribute, but expect_equal() didn’t.
Moreover, expect_equal() has some tolerance when comparing, whereas expect_identical() does not.
## ----- PASSED : <-->
## call| expect_equal(1e-10, 0)## ----- FAILED[data]: <-->
## call| expect_equal(1e-10, 0, tolerance = 1e-12)
## diff| Attributes differ## ----- FAILED[data]: <-->
## call| expect_identical(1e-10, 0)
## diff| Attributes differEven if we save the same object in different locations in memory (env = environment), the two objects will be not identical.
## ----- PASSED : <-->
## call| expect_equal(a, b)## ----- FAILED[attr]: <-->
## call| expect_identical(a, b)
## diff| Equal environment objects, but with different memory locationSpecial comparisons
There a lot of test cases when a result is expected to be TRUE, FALSE or NULL.
Obviously, we could use expect_equal() and write use TRUE, FALSE or NULL as the second argument.
To make it more convenient, there are expect_true(), expect_false(), expect_null() functions.
## ----- PASSED : <-->
## call| expect_true(a)## ----- FAILED[data]: <-->
## call| expect_false(a)
## diff| Expected FALSE, got TRUE## ----- PASSED : <-->
## call| expect_null(A$c)Calling of a function
Obviously, in the test, we can call any visible function, for example a built-in function:
## ----- PASSED : <-->
## call| expect_equal(as.numeric("32"), 32, info = "testing of a function")
## info| testing of a functionIn this example, it is worth noticing that comparison takes also type of data into account. If the types of target (expected) and current (under test) objects do not match, the test case will fail.
## ----- FAILED[data]: <-->
## call| expect_equal(as.numeric("32"), "32", info = "testing of a function")
## diff| Modes: character, numeric
## diff| target is character, current is numeric
## info| testing of a functionExpecting an error
We can also test if a function will cause an error, stop and print a message.
## ----- PASSED : <-->
## call| expect_error(stop("something went wrong"))Moreover, we can check if the error message was as we expected.
## ----- PASSED : <-->
## call| expect_error(stop("something went wrong"), pattern = "something")If the message pattern differs from the expected pattern, the test case will fail because of mismatch of the error / exception
message (FAIL[xcpt]).
## ----- FAILED[xcpt]: <-->
## call| expect_error(stop("something went wrong"), pattern = "nothing")
## diff| The error message:
## diff| 'something went wrong'
## diff| does not match pattern 'nothing'Also if we expect an error, but there is none, the test case will fail.
## ----- FAILED[xcpt]: <-->
## call| expect_error(1/0)
## diff| No errorWe can also expect_silent() (no error), expect_warning() or expect_message().
15.2.4 Test driven development by example
Now let us take a more sophisticated example and define a conversion function from meters to feet. This function should calculate feet based on a distance given in meters. To understand the development process of this function, we will do it step by step.
Core functionality
We can start with a functional test and empty function.
library("tinytest")
meters2feet <- function(x) {} # initial function definition
expect_equal(meters2feet(1), 3.28084) # the first test case ## ----- FAILED[data]: <-->
## call| expect_equal(meters2feet(1), 3.28084)
## diff| Modes: numeric, NULL
## diff| Lengths: 1, 0
## diff| target is numeric, current is NULLThe function will fail the test case (1/1).
We can just return a hard coded number (in most cases, a very bad practice!) to pass the test.
## ----- PASSED : <-->
## call| expect_equal(meters2feet(1), 3.28084)Obviously, the function will pass the test case now (0/1). We are obviously not done. Our function is rather useless and having one test case is usually not enough. Let’s add more functional tests and include a calculation.
## ----- PASSED : <-->
## call| expect_equal(meters2feet(0), 0)## ----- PASSED : <-->
## call| expect_equal(meters2feet(1/3.28084), 1)## ----- PASSED : <-->
## call| expect_equal(meters2feet(1), 3.28084)It seems that we are doing well (0/3).
Error handling
If we want to have domain-specific messages for wrong arguments of our function, we need to define error handling.
We will start with an invalid value, defining both a test case and extending the function.
meters2feet <- function(x) {
if (x < 0) {
stop("The distance must be a non-negative number.")
}
return(3.28084 * x)
}
expect_error(meters2feet(-0.1)) ## ----- PASSED : <-->
## call| expect_error(meters2feet(-0.1))## ----- PASSED : <-->
## call| expect_equal(meters2feet(0), 0)## ----- PASSED : <-->
## call| expect_equal(meters2feet(1/3.28084), 1)## ----- PASSED : <-->
## call| expect_equal(meters2feet(1), 3.28084)Now, we pass all test cases again (0/4 failed).
Now, we will deal with the wrong type. We will accept both numeric values only. And this will lead us to the final solution.
Final solution
The following definition we can consider as the final solution for this example (0/6). If you would like to extend it, you could add a test case and modify the function.
library("tinytest")
meters2feet <- function(x) {
if (!is.numeric(x)) {
stop("The distance must be a number.")
}
if (x < 0) {
stop("The distance must be a non-negative number.")
}
return(3.28084 * x)
}
# if tests are in meters2feet_tinytest.R file,
# you can just run the tests using run_test_file("meters2feet_tinytest.R")
expect_error(meters2feet("a")) ## ----- PASSED : <-->
## call| expect_error(meters2feet("a"))## ----- PASSED : <-->
## call| expect_error(meters2feet("1"))## ----- PASSED : <-->
## call| expect_error(meters2feet(-0.1))## ----- PASSED : <-->
## call| expect_equal(meters2feet(0), 0)## ----- PASSED : <-->
## call| expect_equal(meters2feet(1/3.28084), 1)## ----- PASSED : <-->
## call| expect_equal(meters2feet(1), 3.28084)Hint: The order should be always, at first checking types, next values (content).
Remark: In this particular task, you could swap the order of checks and it will still work. Try it out and find out why it works.