Chapter 20 Additional Exercises (EX)
This last chapter has to be seen as an add-on to the previous chapters and contains some more small exercises for different topics. These exercises can be used for self-learning and practicing.
Reto’s note: I’m currently testing whether including these additional tasks in the discdown learning resource is the best we can do, but I kind of think it makes most sense to publish/maintain these exercises alongside with the main manuscript.
If it works (many thanks to my wonderful group of students this year) I’ll try to work on that and add additional exercises for the previous chapters as well.
10-EX Lists & Data Frames
Let’s juggle around a little bit with lists:
- create lists
- subset lists
- modify lists
- coerce lists
Create Lists
Create unnamed lists
The function list() allows us to create a list. The input to list() is
a comma separated sequence of objects. Each input is stored in the list
in the same order as entered. An example:
## [[1]]
## [1] "A"
##
## [[2]]
## [1] 2
##
## [[3]]
## [1] "drei"The first list element gets the "A", the second the 2, and the third one the "drei".
As we have not set any names, the first element is element [[1]], the second [[2]] and so far, and so on.
Exercises: Create the following three lists (lst1, lst2, lst3):
## [[1]]
## [1] "Eins"
##
## [[2]]
## [1] "Zwei"
##
## [[3]]
## [1] "Drei"Solution.
## [[1]]
## [1] "Eins"
##
## [[2]]
## [1] "Zwei"
##
## [[3]]
## [1] "Drei"## [[1]]
## [1] "Eins" "Zwei" "Drei"Solution.
## [[1]]
## [1] "Eins" "Zwei" "Drei"## [[1]]
## [1] NA
##
## [[2]]
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9
##
## [[3]]
## [1] 1 2 3 4 5 6 7 8 9 10Solution.
# Solution for 'lst3'
# Element 1 is simply 'NA',
# element 2 a small matrix,
# and element 3 an integer sequence 1:10.
lst3 <- list(NA, matrix(1:9, ncol = 3), 1:10)
lst3## [[1]]
## [1] NA
##
## [[2]]
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9
##
## [[3]]
## [1] 1 2 3 4 5 6 7 8 9 10Create named lists
As for vectors, we can specify names for list elements (either for all, or none of them).
This can be done by providing an additional name when calling list() by simply calling
something like list(first = 1, second = 2, third = 3). Note: if the names (e.g., first)
do not contain spaces (blanks) no quotation marks ("first") are needed. If you use blanks,
you need to set the name into quotes!
Exercises: Create the following two list named1, named2:
## $given
## [1] "Jochen"
##
## $family
## [1] "Muster"
##
## $age
## [1] 35Solution.
## $given
## [1] "Jochen"
##
## $family
## [1] "Muster"
##
## $age
## [1] 35What we could have done instead is to create an unnamed list and add the names later on. This works but is not recommended.
# Create an unnamed list
named1x <- list("Jochen", "Muster", 35)
# And now add the names
names(named1x) <- c("given", "family", "age")
named1x## $given
## [1] "Jochen"
##
## $family
## [1] "Muster"
##
## $age
## [1] 35## [1] TRUE## $`A matrix`
## [,1] [,2] [,3]
## [1,] 1 1 1
## [2,] 1 1 1
## [3,] 1 1 1
##
## $`A sequence`
## [1] -5 -3 -1 1 3 5Subset Lists
Next is list subsetting. To subset lists, we need a useful list. You should be able to copy & paste the following lines of code into your R session and use this object later on.
What we do here: create an empty list animals <- list() (call length();
length will be 0) and add some lists with information about specific animals.
At the end we have something like a “nested list” - each entry of the list
animals itself is another list with some properties/features of the animal
iteself.
animals <- list()
# Adding a lion
animals$lion <- list(class = "predator", deadly = TRUE, eyes = 2, where = "Africa", note = "deadly, do not cuddle")
# Adding a cat
animals$cat <- list(class = "predator", deadly = FALSE, eyes = 2, note = "can be cuddled")
# Adding a lovely spider
animals$tarantula <- list(class = "predator", deadly = FALSE, eyes = 8, where = "Africa", note = "hairy")
# An ostrich (Strauss)
animals$ostrich <- list(class = "pray", deadly = FALSE, eyes = 2, where = "Australia", note = "big running bird") Once you have created the object animals you can, of course, call the print() function. But
the output is rather long and, therefore, not shown here.
Subsetting on lists can be done in multiple ways. Using [...], [[...]], and $, by index,
logical vectors, or name. Try to answer the following questions:
- What does
animals["lion"]return us (class, length, …) - What does
animals[["lion"]]return us (class, length, …) - What does
animals$lionreturn us (class, length, …)
Solution. When using [...] we get a reduced (subsetted) list with fewer
elements, in this case the list animals but with only one entry, the one
for "lion". Let’s check:
# Using single square brackets ([...]):
c(length = length(animals["lion"]),
class = class(animals["lion"]),
typeof = typeof(animals["lion"]))## length class typeof
## "1" "list" "list"## [1] "lion"In contrast, [[..]] and $ (they are both the same) return us the
content of a specific list element. Thus, when calling animals[["lion"]]
we get a list of length 5 as this is now the list
with the properties of the lion itself. Let’s check:
# Using double square brackets ([[...]]):
c(length = length(animals[["lion"]]),
class = class(animals[["lion"]]),
typeof = typeof(animals[["lion"]]))## length class typeof
## "5" "list" "list"# Using the dollar operator
c(length = length(animals$lion),
class = class(animals$lion),
typeof = typeof(animals$lion))## length class typeof
## "5" "list" "list"## [1] "class" "deadly" "eyes" "where" "note"All three commands above work on the first level of the list. As we have “lists in a list” we can, of course,
also access elements of these inner lists. Therefore, we need two indices, first one to subset the outer list
(animals), then one to access the elements of the inner one (e.g., the information about the lion).
Again, some questions to think about (or try out):
- What does
animals["lion"]["eyes"]return (class, length, content, …) - What does
animals[["lion"]][["eyes"]]return (…) - What does
animals$lion$eyesreturn (…)
Solution. Let’s see what the first one does:
## $<NA>
## NULLWhy? We first reduce the list animals and only extract the entry "lion". This gives us a
list with one entry (the one for "lion"). From this list we now try to access "eyes", however,
this object does not exist (there is only one entry "lion"). Thus, an ‘NA’/NULL list is returned.
In contrast, the second one does something useful. With double brackets we
access the content. Thus, animals[["lion"]] gives us the list with the
properties of the lion (),
from which we can extract the entry "eyes".
## [1] 2c(length = length(animals[["lion"]][["eyes"]]),
class = class(animals[["lion"]][["eyes"]]),
typeof = typeof(animals[["lion"]][["eyes"]]))## length class typeof
## "1" "numeric" "double"The yields for animals$lion$eyes which does the very same.
We would now like to get some list entries (the data itself, an atomic vector with the character string, logical value, or numeric value we defined above). Exercise: extract the information for the following two elements:
- Subset the number of eyes of the tarantula
- Subset the additional
noteI’ve written for the ostrich
Solution. To access the information about tarantula we can use animals[["tarantula"]] or animals$tarantula.
The latter one is the preferred way and will be used here. This returns us a list, from which we can,
again, extract a specific element, here ...$eyes.
## [1] 8The same can be done for the note for the ostrich:
## [1] "big running bird"Loop over Lists
Given the list animals from above: let us write a for loop which loops over the list.
We are interested in whether or not an animal is deadly.
- Write a loop
for (n in names(animals)) { ... }and try to access the elementdeadlyusingn(character). Print the name of the animal ifdeadly = TRUE. - Try to do the same by writing a loop
for (i in seq_along(animal)) { ... }.iwill be an integer over1, 2, ..., length(animal). Again, print the name of the animal if the animal is deadly.
Solution. Let us start slowly. The for loop over n does the following:
## [1] "lion"
## [1] "cat"
## [1] "tarantula"
## [1] "ostrich"We know that we can access a specific list element using animals[[<name>]]. And n is this name.
In addition, we would like to access deadly. As this is always the same, we can also use the $
operator inside the loop. Let’s do a simple print first:
for (n in names(animals)) {
print(animals[[n]]$deadly)
print(paste("Is the", n, "deadly?", animals[[n]]$deadly))
}## [1] TRUE
## [1] "Is the lion deadly? TRUE"
## [1] FALSE
## [1] "Is the cat deadly? FALSE"
## [1] FALSE
## [1] "Is the tarantula deadly? FALSE"
## [1] FALSE
## [1] "Is the ostrich deadly? FALSE"All we need in addition is an if condition.
for (n in names(animals)) {
# If this is TRUE
if (animals[[n]]$deadly) {
print(paste("The", n, "seems to be deadly"))
}
}## [1] "The lion seems to be deadly"We can do the same using an index instead of the name. It makes the thing a bit more complicated as we now don’t know the name of the animal anymore and have to extract this one as well. Let’s start simple:
## [1] "lion"
## [1] "cat"
## [1] "tarantula"
## [1] "ostrich"Ok, that (names(animals)[i]; subsetting by index on a character vector) gives us
the name of the animal. We could now use this name to do the very same as above (as we have now
the same information as stored on n in the first loop), or we simply use the index i:
for (i in seq_along(animals)) {
if (animals[[i]]$deadly) {
print(paste("Uh, the", names(animals)[i], "seems to be deadly"))
}
}## [1] "Uh, the lion seems to be deadly"Could be a bit tricky: We have also learned about lapply() and sapply(). We could do someting
similar using lapply() or sapply(). Try to write a small custom function
is.deadly(x) which gets one input x (the list with the properties of e.g., the lion).
In this list there is the entry deadly. If the animal is deadly, return "The <name> is deadly",
else "The <name> is not deadly.".
Once you have function which works, try to use this function in combination with lapply and call:
Solution. This exercise has two steps. First, we need a function which takes up e.g., animals$lion and
then returns a string. Depending on what is stored within animals$lion the return value
is different. Let’s start with this function I call is.deadly().
x should now be a list and contain the entry deadly. We could add some sanity checks
to be sure that’s true:
is.deadly <- function(x) {
# if x is no list: return NULL
if (!is.list(x)) { return(NULL) }
# Also return NULL if 'deadly' is not in the names of the list 'x'
if (!"deadly" %in% names(x)) { return(NULL) }
# Else ...
}And now do the rest. All we have to do is to access x$deadly:
is.deadly <- function(x) {
# if x is no list: return NULL
if (!is.list(x)) { return(NULL) }
# Also return NULL if 'deadly' is not in the names of the list 'x'
if (!"deadly" %in% names(x)) { return(NULL) }
# Else ...
if (isTRUE(x$deadly)) {
res <- "This animal is deadly"
} else {
res <- "Is not deadly"
}
return(res)
}If we now apply the function on animals$lion and animals$cat or something else we get:
## [1] "This animal is deadly"## [1] "Is not deadly"## NULLPerfect, we can use this with lapply or sapply:
## $lion
## [1] "This animal is deadly"
##
## $cat
## [1] "Is not deadly"
##
## $tarantula
## [1] "Is not deadly"
##
## $ostrich
## [1] "Is not deadly"## lion cat tarantula
## "This animal is deadly" "Is not deadly" "Is not deadly"
## ostrich
## "Is not deadly"The function is.deadly() is now applied once for each element in the list animals.
Coerce Lists
We have learned about coercion (e.g., as.character(3) or as.integer(3.5)). Lists can also be coerced. We can
convert lists into matrices, data frames, but we can also coerce vectors into lists. An example:
Coerce vector to list
I create myself a numeric vector 1:5 and coerce it into a list.
## [[1]]
## [1] 1
##
## [[2]]
## [1] 2
##
## [[3]]
## [1] 3
##
## [[4]]
## [1] 4
##
## [[5]]
## [1] 5In this special case we get a list of the same length as the original vector - each list entry contains one value. Useful? Sometimes but not that important. We can revert this:
## [1] 1 2 3 4 5.. to get the integer vector again.
Coerce list to data frame
Sometimes more important is to convert lists to data frames and back. Let’s try to set up a
small list lst with four entries, all named, and each of length 3:
lst <- list(name = c("Jochen", "Anna", "Ursula"),
gender = c("male", "female", "female"),
has_kids = c(TRUE, FALSE, TRUE),
zip_code = c(6020, 6021, 1031))
lst## $name
## [1] "Jochen" "Anna" "Ursula"
##
## $gender
## [1] "male" "female" "female"
##
## $has_kids
## [1] TRUE FALSE TRUE
##
## $zip_code
## [1] 6020 6021 1031Try what happens if you call as.data.frame(lst). Store the return on a new object
and investigate the object (str(), summary(), class(), dim()).
Afterwards, try to call as.list on whatever as.data.frame returned you. Call
str() again. Is it the same object as before?
Solution. as.data.frame(lst) converts the list into a data frame (if possible).
Thus, the result should be a data frame with 3 observations and 4 variables.
Why? Well, our list has;
- 4 entries, each will be converted into a variable
- 3 observations in each list entry (e.g.,
c("male", "female", "female")) and therefore the data frame will have three rows.
## name gender has_kids zip_code
## 1 Jochen male TRUE 6020
## 2 Anna female FALSE 6021
## 3 Ursula female TRUE 1031## [1] 3 4## [1] "data.frame"## 'data.frame': 3 obs. of 4 variables:
## $ name : chr "Jochen" "Anna" "Ursula"
## $ gender : chr "male" "female" "female"
## $ has_kids: logi TRUE FALSE TRUE
## $ zip_code: num 6020 6021 1031As a data.frame is actually an extension of a list, we are also always able to convert it back to a list.
## $name
## [1] "Jochen" "Anna" "Ursula"
##
## $gender
## [1] "male" "female" "female"
##
## $has_kids
## [1] TRUE FALSE TRUE
##
## $zip_code
## [1] 6020 6021 1031And, is it the same?
## [1] TRUENot exactely. If you look close you can see that lst_from_df now contains a factor
variable. This happens in as.data.frame() which uses stringsAsFactors = TRUE by default.
If we would to it as follows, it should be the very same at the end:
df <- as.data.frame(lst, stringsAsFactors = FALSE)
lst_from_df <- as.list(df)
identical(lst, lst_from_df)## [1] TRUECreate Data Frames
Create data frames ‘from scratch’
Instead of creating lists, we can also create data frames using the data.frame() function.
As data frames are based on lists, creating lists and data frames is very similar but there
are some important differences.
- Data frames are always rectangular (as matrices).
- Data frames have to be named. Unnamed data frames do not exist.
An example:
data.frame(city = c("Vienna", "Paris", "Zurich"),
country = c("Austria", "France", "Switzerland"),
capital = c(TRUE, TRUE, FALSE))## city country capital
## 1 Vienna Austria TRUE
## 2 Paris France TRUE
## 3 Zurich Switzerland FALSEExercises: Try to create the following data frames (df1, df2, df3):
## name manufacturer release
## 1 Nintendo Switch Nintendo 2017
## 2 Atari 2600 Atari 1977
## 3 Xbox Microsoft 2001Solution.
df1 <- data.frame(name = c("Nintendo Switch", "Atari 2600", "Xbox"),
manufacturer = c("Nintendo", "Atari", "Microsoft"),
release = c(2017, 1977, 2001))
df1## name manufacturer release
## 1 Nintendo Switch Nintendo 2017
## 2 Atari 2600 Atari 1977
## 3 Xbox Microsoft 2001A hint for df2: data frames have to be rectangular. If we give R vectors of different lenghts
when calling data.frame(), R tries to recycle (reuse) the elements until the length of all vectors
match. Can be used here.
## month season
## 1 Dez Winter
## 2 Jan Winter
## 3 Feb WinterSolution. What we do here: we ask for a data frame with two variables (columns). The data for the
variable month is a character vector of length 3, the one for season only a character
vector of length 1. Thus, R simply recycles the last value.
## month season
## 1 Dez Winter
## 2 Jan Winter
## 3 Feb WinterHint: you may use month.abb which gives you the names of the months, and you may think
about using rep() to create the variable for season.
## month season
## 1 Jan Winter
## 2 Feb Winter
## 3 Mar Spring
## 4 Apr Spring
## 5 May Spring
## 6 Jun Summer
## 7 Jul Summer
## 8 Aug Summer
## 9 Sep Autumn
## 10 Oct Autumn
## 11 Nov Autumn
## 12 Dec WinterSolution. We can use rep() to repeat one specific element \(N\) times (e.g., rep("Winter", 10)), but we
can also use rep() to repeat the entries of a vector as often as we need it. Here, we have the
“data” vector c("Winter", "Spring", "Summer", "Autumn", "Winter") and repeat the first element
twice, the second, third and fourth 3 times each, and the last one only once ("Winter" for the month "Dez")
to create the following:
df3 <- data.frame(month = c(month.abb),
season = rep(c("Winter", "Spring", "Summer", "Autumn", "Winter"), c(2, 3, 3, 3, 1)))
df3## month season
## 1 Jan Winter
## 2 Feb Winter
## 3 Mar Spring
## 4 Apr Spring
## 5 May Spring
## 6 Jun Summer
## 7 Jul Summer
## 8 Aug Summer
## 9 Sep Autumn
## 10 Oct Autumn
## 11 Nov Autumn
## 12 Dec WinterCreate data frames from vectors
Instead of writing the ‘data/information’ directly into the data.frame() function (‘from scratch’;
e.g., data.frame(month = c("Dez", "Jan", "Feb"), season = "Winter")) we can also create
data frames based on existing vectors.
Given the following four vectors (you can copy & paste them) which contain some information about dinosaurs (source: dinodatabase.com, accessed 2019-12-07) and a modern MAN coach (Reisebus; man.eu, accessed 2019-12-07):
name <- c("Tyrannosaurus", "Velociraptor", "Stegosaurus", "Ultrasauros", "MAN Lion's Coach")
height_m <- c(7.0, 0.6, 3.4, 16.2, 3.87)
length_m <- c(15.2, 1.8, 9.1, 30.5, 12.101)
weight_kg <- c(6350, 113, 2722, 63500, 19700)… create the following two data frames (dino1 and dino2). Note that the names
of the variables differ:
## name height_m length_m weight_kg
## 1 Tyrannosaurus 7.00 15.200 6350
## 2 Velociraptor 0.60 1.800 113
## 3 Stegosaurus 3.40 9.100 2722
## 4 Ultrasauros 16.20 30.500 63500
## 5 MAN Lion's Coach 3.87 12.101 19700## name height length weight
## 1 Tyrannosaurus 7.00 15.200 6350
## 2 Velociraptor 0.60 1.800 113
## 3 Stegosaurus 3.40 9.100 2722
## 4 Ultrasauros 16.20 30.500 63500
## 5 MAN Lion's Coach 3.87 12.101 19700Solution. As if we create lists or matrices (cbind(), rbind()) we can simply call
data.frame() with a set of vectors as input, separated by commas. As all
vectors do have a name, R uses these names as variable names. Thus, all we
have to do in the first case is:
## name height_m length_m weight_kg
## 1 Tyrannosaurus 7.00 15.200 6350
## 2 Velociraptor 0.60 1.800 113
## 3 Stegosaurus 3.40 9.100 2722
## 4 Ultrasauros 16.20 30.500 63500
## 5 MAN Lion's Coach 3.87 12.101 19700The second version differs as the names are slightly different. We could,
of course, rename the variables of the object dino1 (names(dino1) <- c(...)) or
we can specify new names when creating the data frame and simply call
data.frame() with inputs <new name> = <vector> as follows:
## name height length weight
## 1 Tyrannosaurus 7.00 15.200 6350
## 2 Velociraptor 0.60 1.800 113
## 3 Stegosaurus 3.40 9.100 2722
## 4 Ultrasauros 16.20 30.500 63500
## 5 MAN Lion's Coach 3.87 12.101 19700One last small exercise: given the following two character vectors …
# Austrias 9 states (Bundesländer)
state <- c("Vienna", "Lower Austria", "Upper Austria", "Styria",
"Tyrol", "Carinthia", "Salzburg", "Vorarlberg", "Burgenland")
country <- c("Austria")… create this data frame:
## state country
## 1 Vienna Austria
## 2 Lower Austria Austria
## 3 Upper Austria Austria
## 4 Styria Austria
## 5 Tyrol Austria
## 6 Carinthia Austria
## 7 Salzburg Austria
## 8 Vorarlberg Austria
## 9 Burgenland AustriaIn addition, create a list (list()) with the same two vectors.
What’s the difference?
Solution. Part one is simply:
## state country
## 1 Vienna Austria
## 2 Lower Austria Austria
## 3 Upper Austria Austria
## 4 Styria Austria
## 5 Tyrol Austria
## 6 Carinthia Austria
## 7 Salzburg Austria
## 8 Vorarlberg Austria
## 9 Burgenland AustriaAgain, as the second vector is “too short” R recycles the element as often as needed. What if we create a list?
## [[1]]
## [1] "Vienna" "Lower Austria" "Upper Austria" "Styria"
## [5] "Tyrol" "Carinthia" "Salzburg" "Vorarlberg"
## [9] "Burgenland"
##
## [[2]]
## [1] "Austria"Two differneces: the elements are, by default not named (lists can be unnamed in contrast
to data frames), and the vector country is not extended. We simply end up with a list
of two elements containing the two vectors as they are.
Now let’s go one step further. Data frames can be coerced to lists. What happens if we create a data frame first, and then coerce it to a list?
## $state
## [1] "Vienna" "Lower Austria" "Upper Austria" "Styria"
## [5] "Tyrol" "Carinthia" "Salzburg" "Vorarlberg"
## [9] "Burgenland"
##
## $country
## [1] "Austria" "Austria" "Austria" "Austria" "Austria" "Austria" "Austria"
## [8] "Austria" "Austria"I’ve set stringsAsFactors = FALSE such that we end up with character vectors. The difference
to the list() call above: the elements are now named, and the second entry of the list (country)
has length 9. The reason is obvious:
- First, the object of class
data.frameis created - with names, and recycled elements. - Second, this data frame which is converted to a list. As the data frame was named, and the data have been extended already, the final list, of course, also contains this information.
Subset Data Frames
Data frames can be subsetted in different ways. Either using list-alike subsetting (which works the very same way as if we subset lists), or matrix-alike subsetting (as data frames are always rectangular).
List-alike subsetting
Let’s start with list-alike subsetting. We have learned that we can use [...], [[...]] and $.
Given this data frame,
dino <- data.frame(name = c("Tyrannosaurus", "Velociraptor", "Stegosaurus", "Ultrasauros", "MAN Lion's Coach"),
height_m = c(7.0, 0.6, 3.4, 16.2, 3.87),
length_m = c(15.2, 1.8, 9.1, 30.5, 12.101),
weight_kg = c(6350, 113, 2722, 63500, 19700),
stringsAsFactors = FALSE)
dino## name height_m length_m weight_kg
## 1 Tyrannosaurus 7.00 15.200 6350
## 2 Velociraptor 0.60 1.800 113
## 3 Stegosaurus 3.40 9.100 2722
## 4 Ultrasauros 16.20 30.500 63500
## 5 MAN Lion's Coach 3.87 12.101 19700try to answer the following questions.
- What does
dino["length_m"]return (class, length, …) - What does
dino[["length_m"]]return (class, length, …) - What does
dino$length_mreturn (class, length, …)
Solution. As for lists, [...] returns a reduced object of the same class. In this case, a data frame.
Not the content of the element we are accessing and is, thus, of class data.frame and length 1 as we
only extract the one variable/column length_m.
## length_m
## 1 15.200
## 2 1.800
## 3 9.100
## 4 30.500
## 5 12.101c(class = class(dino["length_m"]),
typeof = typeof(dino["length_m"]),
length = length(dino["length_m"]))## class typeof length
## "data.frame" "list" "1"In contrast, [[...]] and $ return us the content of this variable.
As length_m is a numeric vector of length 5, we should end up with a vector
of this class and length:
## [1] 15.200 1.800 9.100 30.500 12.101## class typeof length
## "numeric" "double" "5"The same is true for [[...]] but in this case the $ operator would be the preferred choice.
Matrix-alike subsetting
Instead, we could also use all the tools we have learned in section Subsetting Matrices. Let’s play around and do
- Subsetting by index,
- subsetting by character,
- and subsetting by logical vectors on the object
dinoabove.
Try to do the following:
- Using indices: extract the first row of the data frame.
- Using characters (and matrix-alike subsetting): extract the column
"name". - Using indices: extract the length of the Tyrannosaurus and the Ultrasauros.
- Create a logical vector (use some logical expression on
dino$height_m) which containsTRUEif the dinosaur was longer than 10 meters andFALSEelse. With this logical vector, (i) extract all rows which belong to these large dinosaurs, and (ii) extract the names of these large (long) dinosaurs (name only, use matrix-alike subsetting).
Solution.
- Extract the first row of the data frame:
## name height_m length_m weight_kg
## 1 Tyrannosaurus 7 15.2 6350- Use characters to extract the
"name"s:
## [1] "Tyrannosaurus" "Velociraptor" "Stegosaurus" "Ultrasauros"
## [5] "MAN Lion's Coach"- Extract the length of two dinosaurs. To be able to do so we either have to find the row-indices of these two, or simply do it manually. E.g.,:
## [1] 15.2 30.5# Nicer: find indices of these two species, then use this
# index vector to extract the length.
idx <- which(dino[, "name"] %in% c("Tyrannosaurus", "Ultrasauros"))
idx## [1] 1 4## [1] 15.2 30.5- Using logical vectors. What we have to do first is to create this logical vector. E.g.,:
## [1] TRUE FALSE FALSE TRUE TRUEwhich we can then use to extract the information. Either all variables/columns, or just some specific (e.g., the name):
## name height_m length_m weight_kg
## 1 Tyrannosaurus 7.00 15.200 6350
## 4 Ultrasauros 16.20 30.500 63500
## 5 MAN Lion's Coach 3.87 12.101 19700## [1] "Tyrannosaurus" "Ultrasauros" "MAN Lion's Coach"Sure, if we have a data frame we would do this differently by calling:
## [1] "Tyrannosaurus" "Ultrasauros" "MAN Lion's Coach"If you do not specify drop = TRUE you’ll get a data frame as return of the
function subset().
Loop over Data Frames
Using basic loop constructs
Sometimes we may need to want to loop over data frames. We can do this
matrix-alike, the same way we have learned to loop over matrices. Write
a loop which loops over all rows of the data frame dino and prints something
like "The Tyrannosaurus was typically 7 meters tall" (requires one for loop
and some matrix-alike subsetting).
Solution. Without a lot of comments:
for (i in 1:nrow(dino)) {
print(paste("The", dino[i, "name"], "was typically",
dino[i, "height_m"], "meters tall"))
}## [1] "The Tyrannosaurus was typically 7 meters tall"
## [1] "The Velociraptor was typically 0.6 meters tall"
## [1] "The Stegosaurus was typically 3.4 meters tall"
## [1] "The Ultrasauros was typically 16.2 meters tall"
## [1] "The MAN Lion's Coach was typically 3.87 meters tall"Loop replacement functions
In addition, we have learned that there are two functions called
sapply() and lapply(). They apply a function to each variable
of the data frame (or, in case of a list, to each element in the list).
Try to call lapply() and sapply() on the object dino and return
the maximum of each variable (max()).
- What do you get? Class, length …
- What’s the difference between
lapply()andsapply()?
Solution. First, we use lapply:
# Calling lapply with named input arguments
res <- lapply(X = dino, FUN = max)
# Or, shorter ...
res <- lapply(dino, max)
res## $name
## [1] "Velociraptor"
##
## $height_m
## [1] 16.2
##
## $length_m
## [1] 30.5
##
## $weight_kg
## [1] 63500## class typeof length
## "list" "list" "4"As we can see, lapply() always returns a list (thus the l in front of apply()).
"Velociraptor" is the maximum as the maximum of a character vector is the last
element when you sort the elements in an alphabetic order.
In this case a named list of length 4. NOTE: the entries are of different
classes (namely ).
We can also see this if we call:
## List of 4
## $ name : chr "Velociraptor"
## $ height_m : num 16.2
## $ length_m : num 30.5
## $ weight_kg: num 63500.. or, as we are talking about lapply, we could also do something like:
## $name
## [1] "character"
##
## $height_m
## [1] "numeric"
##
## $length_m
## [1] "numeric"
##
## $weight_kg
## [1] "numeric"In contrast, sapply() tries to simplify the return (s in front of apply()). Thus, if we do the same with
sapply() we get:
# Calling sapply with named input arguments
res <- sapply(X = dino, FUN = max)
# Or, shorter ...
res <- sapply(dino, max)
res## name height_m length_m weight_kg
## "Velociraptor" "16.2" "30.5" "63500"## class typeof length
## "character" "character" "4"We get the same information as with lapply(), but R simplifies the return (the four maxima)
and packs all four values into one single vector. As a vector can only contain data of one type,
and the maximum of name is "Velociraptor" R has to coerce all elements to character and
we end up with a character vector.
Coerce Data Frames
Check the examples in Coerce Lists above which shows how to coerce between lists and data frames.
12-EX Reading & Writing
This section contains a set of simple examples to practice reading and writing (see Reading & Writing). As there is (basically) no limitation what we can read and write using R, however, in this course we focus on:
- Rs binary file format (
rdaandrds) - csv files and all it’s possible formats
- quickly checking out the ability to read/write xls/xlsx files
Rs binary file formats
As you all know there are two different binary file types, files ending
on .rda (also sometimes called .RData or .rdata) and files ending
on .rds. Remember: the file extension (e.g,. .rda) is not really
important but gives you some information about the file type and which
function you may use to load the file.
- In case of
rda:save()to save objects,load()to load a file. - In case of
rds:saveRDS()to save an object,readRDS()to load a file.
Save and load an rda file
Let us assume we have two objects called A and B for simplicity.
A. is an integer sequence, B a small data frame.
The Exercise:
- Store the two objects into a binary R file,
both at the same time into one single called
data_AB.rda. - After you saved the data, call
rm(list = objects()). This deletes all the objects from your curret workspace such that you can see if they are re-created later on. - Last but not least, load the file again. Can you find both,
AandBagain in your current R session (workspace)?
Solution. Before we start: let’s check the objects in our workspace. Should be empty, as I just flushed everything.
## character(0)# Create the two objects A and B
A <- -5:5
B <- data.frame(name = c("Herbert", "Klara"), age = c(35, 54))If we call objects() now we will get a character vector with
all the names of all defined objects, here "A" and "B".
## [1] "A" "B"(1) To store both objects at the same time we need to use
the rda file type, as rds only allows to store one single
file. All we have to do is to call:
We could now check if we really created the file. To do so, we could
use file.exists() which returns a logical vector with TRUEs and
FALSEs. Let’s see:
## [1] "Yey, the file exists!"(2) We will now delete everything in our workspace once more.
(3) … and re-load the object. Nothing easier than that:
## Loading objects:
## A
## B## [1] -5 -4 -3 -2 -1 0 1 2 3 4 5## name age
## 1 Herbert 35
## 2 Klara 54QUESTION: where have you stored your file "data_AB.rda"? Remember,
"data_AB.rda" is a relative path. Thus, it is relative to your current
working directory. If your current working directory is
"C:/Users/Max/Documents" the file will be located in this folder!
Save and load an rds file
Handling rds files is very simple to the handling of rda files except that
we can only store one object at a time, and the names are not preserved. Above,
we can see that "A" and "B" have been re-created as "A" and "B" after
laoding the rda file. In case of an rds file, this is slightly different.
The Exercises:
Let us, once more, take the two very simple objects A and B
from the previous exercise (see below) and do the following:
- Store both objects into separate
rdsfiles, e.g., call themdata_A.rdsanddata_B.rds(bad names, in real life you should of course use more meaningful file names). - After you stored the data, delete all objects
in your workspace (
rm(list = objects())) and load the two files, store the result asdata_Aanddata_B.
# Clear workspace first
rm(list = objects())
# The two objects we use in this small exercise
A <- -5:5
B <- data.frame(name = c("Herbert", "Klara"), age = c(35, 54))Solution. (1) Let’s keep this short. All we have to do is to replace save(A, B, file = ...)
by two calls saveRDS(A, ...) and saveRDS(B, ...). Remember, it is impossible
to store both, A and B into the same rds file as they are.
Small excursion/question: remember, that we called save(A, B, file = ...) using an explicitly
named argument file = ... when calling the function? Why don’t we need this
when calling saveRDS()? Well, if you look into the documentation of both
functions (?save; ?saveRDS) you should see the difference:
save(..., list = character(), file = stop("'file' must be specified"), ...)saveRDS(object, file = "", ...)
save() expects that everything which is not named is simply an object. Thus, if
you call save(A, B, "data.rda") you will get the error message
“Error in save(A, B, "data.rda") : object ‘foo.rda’ not found”. The reason is that
R expects that there is an object A (yep), B (yep) and an object called
data.rda (fails). If we hand over characters to the function save() R tries
to evaluate them (e.g., if we provide "data.rda" it tries to find an object named
data.rda which, of course, does not exist in our case and causes the error.
Thus, save() requires the explicit definition of file = .... In contrast,
saveRDS() expects one object (first argument) followed by a second argument
which is the file name. Thus, saveRDS(object, "filename.rds") works perfectly.
(2) All we have to do is to load the data again. Remember: readRDS() returns the
object (does not store it into your workspace as load() does):
## [1] -5 -4 -3 -2 -1 0 1 2 3 4 5… prints the vector originally called A as we do not assign it a new object.
What we need to do here is:
# Load both data sets
data_A <- readRDS("data_A.rds")
data_B <- readRDS("data_B.rds")
# Check workspace
objects()## [1] "A" "B" "data_A" "data_B"… done.
Store “multiple” objects into one rds file
Wait, is the title misleading? Haven’t we just learned that we can only
store one single object into an rds file? Well, that’s true, there
is no exception. But imagine we would like to store the vector (called A)
and the data frame (called B) from above into one rds file not to have
two separate files.
The Exercise:
We cannot use rds to store multiple objects, but what we can do is to pack
different objects into one list object, and then store this list into one rds file.
Let us do the following:
- Store
AandBinto a new list object (e.g., calledlst). - The list
lstshould have two named entries, namely an element"A"and one"B". - Save the list into an
rdsfile. - Clean your workspace (
rm(list = objects())). - Load the list, see if you lost any data (hopefully not).
Solution. Well, it is straight forward except that we have to create the list first. For details, please check out chapter Lists & Data Frames. We can do this as follows:
# Create a named list
lst <- list(A = A, B = B)
# Save the list into a new rds file
saveRDS(lst, "data_list.rds")
# Clear workspace
rm(list = objects())
# Check objects in our workspace (empty)
objects()## character(0)We can now, of course, load our list again:
## [1] -5 -4 -3 -2 -1 0 1 2 3 4 5## name age
## 1 Herbert 35
## 2 Klara 54This can be a nice solution if you have a bunch of different objects which belong to each other. This approach allows you to:
- Store complex information: a vector and a data frame and a date when the data set has been created, and even a function you would like to store used to process this data set if needed,
- Improve interpretability of the object as the names
tell you what the objects are intended for; e.g.,
data,model,result, … - You don’t have to remember the name of the objects (which would be the
case if you use
rda).
Read CSV files
As we have learned in the “Reading & Writing” chapter
one commonly used and easy to handle format is the CSV file format. CSV files
may look unique, and the file extension does not even have to be .csv, but
as soon as we have an ASCII file with a well-defined tabular structure we can
use read.csv() or read.table() to import the data.
Side note: you may come along the name TSV (tabular separated value) which simply means that tabulators are used to separate the values rather than commas (or spaces, or semicolons, …).
Bloomington Stolen Gun Data
There’s a small data set called “BPD_stolen_guns.csv”, a data set which contains information from the Bloomington Police Department (source: data.gov).
The Exercise:
- Download the data set “BPD_stolen_guns.csv”. Check the file format by opening the file in a text editor or in the code editor of RStudio.
- Import the data set using
read.csv()with all the parameters you need. - Try to answer the question: from where have most guns been stolen (
Stolen Fromcolumn)?
Solution. (1/2) Well, this is a CSV file in the ‘classical’ format.
- We have a header line (column description)
- Values are separated by commas
- No comments (meta information)
Thus, all we have to do is:
## [1] 85 10(3) In the CSV file the column with the information where the gun has been stolen
is stored in the column Stolen From. When reading the data set, R replaces the
space/blank with a dot (.). Thus, the column is then called Stolen.From in out
data frame guns.
What we can do to find out where guns are most likely be stolen we can e.g., count the occurrence of the different values in this column:
##
## RESIDENCE Residence Stolen Vehicle Unknown VEHICLE
## 18 36 3 1 6
## Vehicle
## 21… and now you can see why R replaces the space/blank with a dot. If there would
be a space ("Stolen From") we would not be able to use the $ operator. Thus, that’s
a good thing, not a bad thing.
As we can see most guns are stolen from “Resicence” (stolen from a flat or house)
followed by “Vehicle” (out of a car/truck).
Problem: as you can see the data set contains "Resicence" and "RESICENCE",
as well as "Vehicle" as "VEHICLE" wherefore we do not get the total sum.
That’s how the data is coded in the original data set downloaded from
data.gov.
We could get around this by setting both to upper or lower case, and then count the occurrence:
##
## residence stolen vehicle unknown vehicle
## 54 3 1 27##
## RESIDENCE STOLEN VEHICLE UNKNOWN VEHICLE
## 54 3 1 27New Orleans Jazz Houses
New Orleans is famous for Jazz. The data set “NewOrleans_JazzHouses.dat” contains coordinates, names, and addresses of houses across the city which have been marked to have once housed the leader of the jazz music industry.
The coordinates are stored as Longitude and Latitude (geographical
coordinates, in degrees). Longitude gives the position on the Earth from
east to west (e.g., Innsbruck is about 11 degrees West of the Greenwich
meridian), the latitude the position south-north (Innsbruck is 47 degrees
from the equator to the north; the north pole is 90 degrees north).
We would like to read the data set such that we are able to
plot(Latitude ~ Longitude, data = ...) (must be read as numeric).
The Exercise
- Download the data set “NewOrleans_JazzHouses.dat” and check the data set format (use a text editor or RStudios code editor).
- Import the data set using
read.csv()orread.table(). - Check the resulting object.
- How many observations (rows) do we have?
- What’s the class of
LongitudeandLatitude? - If they are not numeric: why not? Adjust your call to
read.csv()/read.table()such that you end up with two numeric variables.
- Try to call
plot(Latitude ~ Longitude, data = ...)on your data set.
Solution. (1) First of all we have to check the content of the data set. The first few lines look as follows:
# --------------------------------
# Point file of houses across the city of New Orleans
# that are marked to have once housed the leaders of
# the jazz music industry.
#
# Source: https://catalog.data.gov/dataset/jazz-houses-e1814
# Downloaded: December 23, 2019
#
# Content:
# - ObjectID: internal object identifier
# - Longitude/Latitude: geographical location
# - Given_Name/Family_Name: persons' names.
# - Address: post address
# --------------------------------
ObjectID; Longitude; Latitude; Given_Name; Family_Name; Address
355; MISSING; MISSING; James ; Brown ; 811 N LIBERTY ST
151; -90.07430; 29.96760; Alphonse ; Picou ; 912 N PRIEUR ST
268; -90.08892; 29.93215; Dave ; Perkins ; 1814 SIXTH ST
73; -90.07999; 29.96236; William J. ; Braun ; 2019 IBERVILLE ST
292; -90.07823; 29.93950; "Professor Longhair" "Fess"; Byrd ; 1738 TERPSICHORE ST As we can see, the .dat file contains tabular data - we can easily read this
using the read.csv()/read.table() methods. All we have to know:
- There is a comment section (lines starting with the character
#). - We have a header (column names).
- The values seem to be separated by
;. - Values are not quoted. There are some quotes, but these quotes belong to special names of specific musicians.
All we have to do is:
# Using read.csv
jazz <- read.csv("data/NewOrleans_JazzHouses.dat",
comment.char = "#",
sep = ";")
head(jazz, n = 2)## ObjectID Longitude Latitude
## 1 355 MISSING MISSING
## 2 151 -90.07430 29.96760
## Given_Name Family_Name
## 1 James Brown
## 2 Alphonse Picou
## Address
## 1 811 N LIBERTY ST
## 2 912 N PRIEUR ST# Same using read.table
jazz <- read.table("data/NewOrleans_JazzHouses.dat",
header = TRUE,
sep = ";")
head(jazz, n = 2)## ObjectID Longitude Latitude
## 1 355 MISSING MISSING
## 2 151 -90.07430 29.96760
## Given_Name Family_Name
## 1 James Brown
## 2 Alphonse Picou
## Address
## 1 811 N LIBERTY ST
## 2 912 N PRIEUR STNote that the two functions have different defaults. We only have to provide
the function input arguments we don’t want to use these defaults.
Well, we now have the data set, but some things are weird, let’s check str():
## 'data.frame': 476 obs. of 6 variables:
## $ ObjectID : int 355 151 268 73 292 266 204 310 96 240 ...
## $ Longitude : chr " MISSING" " -90.07430" " -90.08892" " -90.07999" ...
## $ Latitude : chr " MISSING" " 29.96760" " 29.93215" " 29.96236" ...
## $ Given_Name : chr " James " " Alphonse " " Dave " " William J. " ...
## $ Family_Name: chr " Brown " " Picou " " Perkins " " Braun " ...
## $ Address : chr " 811 N LIBERTY ST " " 912 N PRIEUR ST " " 1814 SIXTH ST " " 2019 IBERVILLE ST " ...LongitudeandLatitudeare not numeric (but factors)- The levels seem to contain dozens of spaces (blanks).
Well, the problem with Longitude and Latitude is that some of the entries
contain MISSING. We can set them to NA by specifying na.strings when calling
read.csv() or read.table(). The second problem results from the fact that R
now splits the values at semicolons (sep = ";") - but keeps leading and trailing
white spaces. We can tell R that it should strip white spaces
(remove unnecessary white spaces before/after a character string).
Let us call read.table() again using the two additional inputs:
# Read the data set again
jazz <- read.table("data/NewOrleans_JazzHouses.dat",
header = TRUE,
sep = ";",
na.strings = "MISSING",
strip.white = TRUE)
str(jazz)## 'data.frame': 476 obs. of 6 variables:
## $ ObjectID : int 355 151 268 73 292 266 204 310 96 240 ...
## $ Longitude : num NA -90.1 -90.1 -90.1 -90.1 ...
## $ Latitude : num NA 30 29.9 30 29.9 ...
## $ Given_Name : chr "James" "Alphonse" "Dave" "William J." ...
## $ Family_Name: chr "Brown" "Picou" "Perkins" "Braun" ...
## $ Address : chr "811 N LIBERTY ST" "912 N PRIEUR ST" "1814 SIXTH ST" "2019 IBERVILLE ST" ...Et voila, problem solved! As we now have the coordinates as numeric values we could try to plot this. Sure, that’s not yet a nice spatial plot (a background map would be nice) but that’s beyond this exercise.
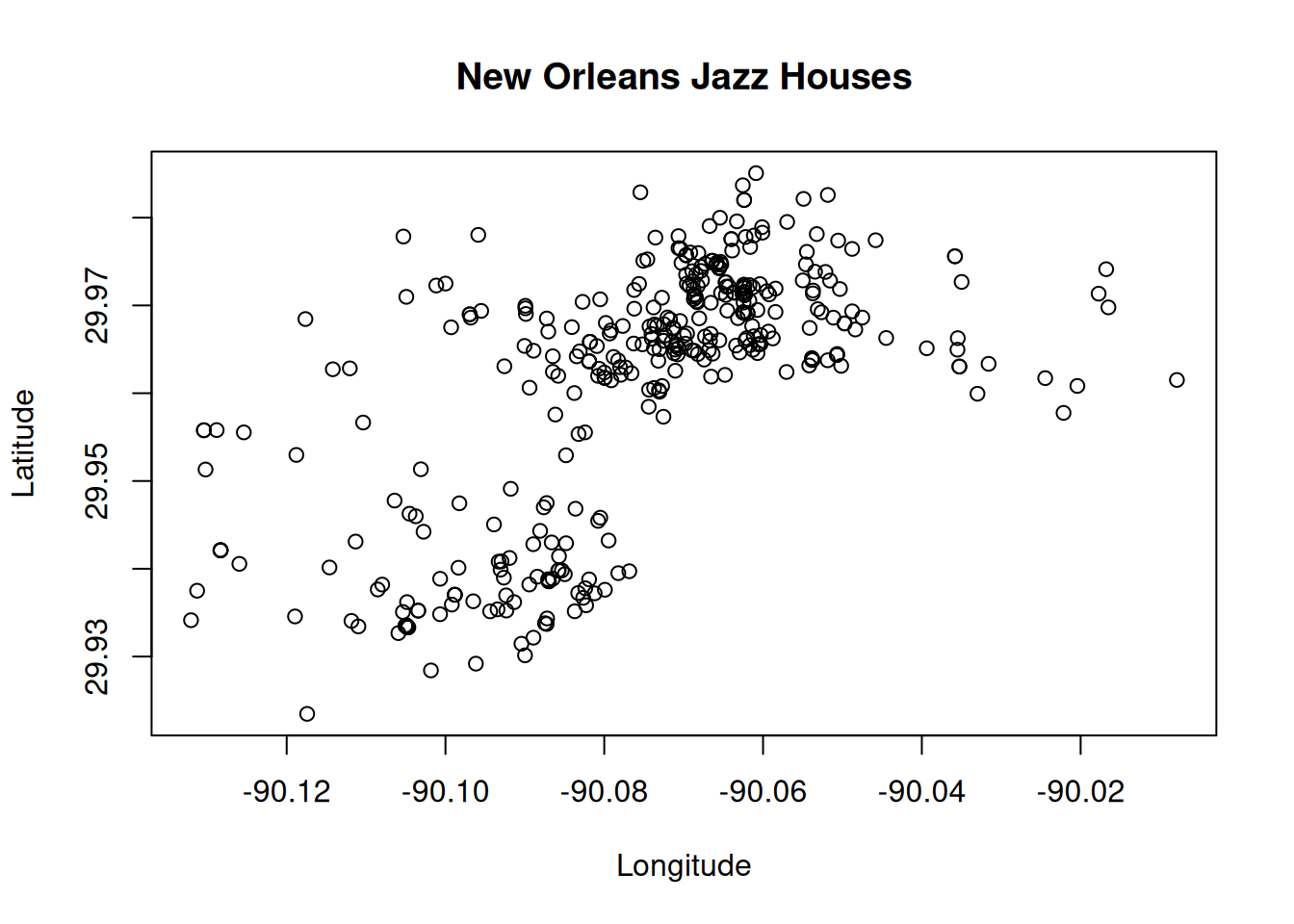
Or draw the last names of the musicians:
plot(Latitude ~ Longitude, data = jazz,
type = "n", # suppresses the dots/points
main = "New Orleans Jazz Houses")
with(jazz, text(Longitude, Latitude, Family_Name, col = "blue"))
Beaver Population, Cros Morne National Park
If Canadians love anything more than hockey, it’s their beavers!

Figure 20.1: Beaver sculpture over the entrance to the Canadian Parliament Building (Wikimedia).
The data set “Beaver_Colonies_GrosMorne.CSV” contains some population counts of beaver colonies in the Gros Morne National Park (source: open.canada.ca).
The Exercise
- Download the data set “Beaver_Colonies_GrosMorne.CSV” and check its format.
- Without manipulating the downloaded
.CSVfile: read the data set using eitherread.csv()orread.table(). - How many active beaver colonies did we have in 2009? How many in 2015?
If a beaver colony is active is indicated with a
"Y"in column"active". - Advanced: can you solve the last question using one simple
aggregate()call with a custom function?
Solution. (1) Well, the file format is a bit tricky. The main reason is that we have
meta information in the first part of the file, but the comments do not have
a specific leading character (e.g., "#"). Thus, we cannot set comment.char
in a way that we can skip this head.
Instead, we could use skip = .... skip allows to skip the first N lines
of a file. In this case the first 22 lines contain meta information, line 23 up
to 162 the rest.
The rest is straight forward: we have a header, and the separator is a semicolon (;).
# Using csv
beaver <- read.csv("data/Beaver_Colonies_GrosMorne.CSV",
sep = ";", skip = 22)
head(beaver, n = 2L)## ID year month day ecoregion type dam lodge browse cutting
## 1 WN_02_2009 2009 11 10 WesternNewfoundland WN2 Y Y Y N
## 2 WN_03_2009 2009 11 10 WesternNewfoundland WN2 N Y Y N
## beaver active comment
## 1 N Y
## 2 N Y(2) To count the number of active beaver colonies we have
to count all "Y"’s in 2009 and 2015, respectively. There are
multiple ways to do so.
subset(), count number of observations (rows)subset()in combination withtable()table()alone should also work.aggregate()with a custom function.
Let us start with the simplest one and subset all observations (rows)
for 2009, where the corresponding value in active is identical to "Y".
We can do the same for 2015, of course.
# Subset
beaver_2009 <- subset(beaver, year == 2009 & active == "Y")
beaver_2015 <- subset(beaver, year == 2015 & active == "Y")
c("Active in 2009" = nrow(beaver_2009),
"Active in 2015" = nrow(beaver_2015))## Active in 2009 Active in 2015
## 21 40That’s it. We could also use the subset in combination with table() to
get the number of "N", "Y", "unsure" for the two years:
beaver_2009 <- subset(beaver, year == 2009) # Only year-subset!
beaver_2015 <- subset(beaver, year == 2015) # Only year-subset!
# Using table
table(beaver_2009$active)##
## N Y unsure
## 28 21 1##
## N Y unsure
## 48 40 1Or, even cooler, simply use table() with two inputs, namely
the year and active on the full data set:
## active
## year N Y unsure
## 2009 28 21 1
## 2015 48 40 1A last possible option (even if a bit too complicated for this simple
question) would be aggregate(). We know that we can use aggregate() to
e.g., calculate the mean for specific groups (e.g., temperature ~ year to
get the average temperature given year).
What we would like to have here is the “number of Ys given year”. Therefore,
we would need a custom function! The function should return the number of "Y"s
of a vector. If this works, we can use our custom function in combination with
aggregate.
# Our custom function
count_Ys <- function(x) {
result <- sum(x == "Y")
return(result)
}
count_Ys(c("N", "N", "Y", "Y", "maybe"))## [1] 2What our function count_Ys() does: given the one input argument x it returns
us the number of "Y"s in the vector x (sum(x == "Y")). All we have to do
now is to call aggregate(active ~ year, data = beaver, FUN = count_Ys).
What this does (pseudo-code):
- Subsets the data set
beaverfor each of the years inyear. - The variable
activeof each subset for eachyear(thusactive ~ year) is extracted and the functioncount_Ysis applied.
… and the result:
## year active
## 1 2009 21
## 2 2015 40Read XLS/XLSX files
Reading an XLS file
We have already came along the "FBI_crime_data.CSV" file in the
Read CSV files section.
Reto, do we really use this data set in the book?
The original data set
(see ucr.fbi.gov; last accessed 2019-12-15)
is actually an XLS file. Thus, let us try to import the same data set from the
original XLS file called
"FBI_crime_data.xls" which can be downloaded here (click).
Note: R base cannot deal with XLS or XLSX, you will need to load
an additional library. Here, we’ll use the readxl package which
comes along with RStudio (thus, you should all have it installed).
Exercise:
- Download the
"FBI_crime_data.xls"data set. - Open the XLS file and check what it contains (use MS Excel, Libre Office, …).
- Load the
readxllibrary by callinglibrary("readxl"). - As soon as you have loaded the library, you can use the function
read_xlsfrom thereadxlpackage/library. - You may need to consult the R documentation for
read_xlsby callinghelp("read_xls")or?read_xlsto see the list of available options. Try to figure out a way to only read the data part of the XLS data set Note:read_xlsreturns a “tibble data frame” (not a pure data frame). You can, however, convert the object into a data frame by callingas.data.frame()on the tibble data frame if that helps you.
Solution. First, let us discuss what we have in the XLS file. If you open the XLS file in your spreadsheet software (Excel) you can see that we not only have a matrix-like data set, but also some additional information (title, subtitle, footnotes).
The only way (?) to solely read the data section is to:
skipthe first three lines,- and only read 20 lines from the XLS file (21 including the header line). This
argument is called
n_maxinread_xls.
Let’s see:
# Reading the FBI data set
library("readxl")
FBI <- read_xls("data/FBI_crime_data.xls", skip = 3, n_max = 20)
# To get a pure data frame ...
FBI <- as.data.frame(FBI)
# Last two observations (rows)
tail(FBI, n = 2L)## Year Population1 Violent\ncrime2 Violent \ncrime \nrate
## 19 20156 320896618 1199310 373.7
## 20 2016 323127513 1248185 386.3
## Murder and\nnonnegligent \nmanslaughter
## 19 15883
## 20 17250
## Murder and \nnonnegligent \nmanslaughter \nrate
## 19 4.9
## 20 5.3
## Rape\n(revised \ndefinition3) Rape\n(revised \ndefinition) \nrate3
## 19 126134 39.3
## 20 130603 40.4
## Rape\n(legacy \ndefinition4) Rape\n(legacy \ndefinition) \nrate4 Robbery
## 19 91261 28.4 328109
## 20 95730 29.6 332198
## Robbery \nrate Aggravated \nassault Aggravated \nassault rate
## 19 102.2 764057 238.1
## 20 102.8 803007 248.5
## Property \ncrime Property \ncrime \nrate Burglary Burglary \nrate
## 19 8024115 2500.5 1587564 494.7
## 20 7919035 2450.7 1515096 468.9
## Larceny-\ntheft Larceny-\ntheft rate Motor \nvehicle \ntheft
## 19 5723488 1783.6 713063
## 20 5638455 1745.0 765484
## Motor \nvehicle \ntheft \nrate
## 19 222.2
## 20 236.9That works well - except that, as you can see, the variable names are ‘weird’.
Why? Well, the column names in the XLS file are multi-line entries - with
some line breaks. These line breaks are read as "\n". In addition, the foot notes
(e.g, 1 or 2) end up as “integers/numbers” at the end of the variable names.
We can, of course, rename all variables, I leave this open to you :). However, what we can see here is that it is possible to read XLS files. As Excel and other spreadsheet programs allow for a lot of features (e.g., footnotes) it can make reading data from XLS/XLSX files challenging if the files are not machine-readable (or not easily machine-readable).